AI-Starter 2.4.15

AI-Starter の最新バージョン 2.4.15 をリリースいたしました。 今回は、いつもよりも多くのアップデートが行われています。
主な更新内容
- モデル
- 画像生成モデル
- UI/UXの改善
- 機能追加と改善
- その他の細かなバグ修正・機能改善
1. モデル
以下のモデルの追加と更新を行いました。
- AWS
- Claude 3.7 Sonnet の Extended Thinking Mode における会話制限の解除
- Nova Premierのサポート
- Azure
- o4-miniのサポート
- GPT-4.1のサポート
- Google
- Gemini 2.5 Flash Previewのサポート
- Gemini 2.5 Pro Previewのサポート
- Gemini 2.0 FlashのモデルIDをエイリアスに更新
- Gemini 2.0 Flash-LiteのモデルIDをエイリアスに更新
- OpenAI
- o4-miniのサポート
- o3のサポート
- GPT-4.1のサポート
- GPT-4.1 Miniのサポート
- GPT-4.1 Nanoのサポート
- GPT-4o Search Previewの「機密情報は入力不可」を削除
- GPT-4o mini Search Previewの「機密情報は入力不可」を削除
追加や更新をご希望の場合、設定変更が必要となることがありますので、サポート窓口までお問い合わせください。 また、OpenAIの「GPT-4o Search Preview」における情報の取り扱いについても、サポート窓口までご連絡ください。 なお、Novaシリーズに関しては、PDF入力時にハルシネーションが発生するAWS側の事象を確認しております。あらかじめご了承ください。
2. 画像生成モデル
AI-Starterの画像生成基盤が大幅に整備されました。 今回は、以下の画像生成モデルの追加と更新を行いました。
- AWS
- Nova Canvasのサポート
- Azure
- DALL-E 3のサポート
- Google
- Imagen 3のサポート
- OpenAI
- GPT Image 1のサポート
Nova Canvasは、Nova系の画像生成モデルです。 今回のアップデートでは、テキストからの画像生成のみ対応しています。 東京リージョンのモデルを有効化してご利用ください。
https://docs.aws.amazon.com/ja_jp/nova/latest/userguide/prompting-image-generation.html
AI-StarterではDALL-E 3は、これまでOpenAIのみサポートしていましたが、今回Azure OpenAIでもサポートしました。
https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/dall-e?tabs=gpt-image-1
GoogleのImagen 3は、Googleの画像生成モデルです。 比較的早い速度で、高品質な画像が生成できます。 言語制限があるため、英語で指示する必要があります。
https://cloud.google.com/vertex-ai/generative-ai/docs/image/overview
OpenAIのGPT Image 1は、最近公開された画像生成モデルです。 上記モデルと異なり、直近に生成した画像に編集を加えることができます。 Azure OpenAIのGPT Image 1は、動作確認ができ次第、サポート予定です。
https://openai.com/index/image-generation-api/
AI-Starterの開発チームの総評は、以下の通りです。
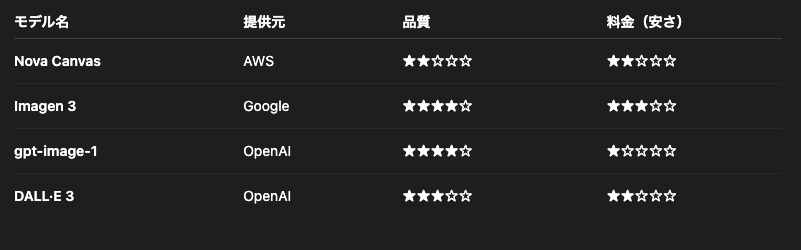
- バランスが取れているのは、Imagen 3
- 高額だが、高品質に対話しながら画像生成できるのは、GPT Image 1
- 低価格で、早く生成できるのは、Nova Canvas
3. UI/UXの改善
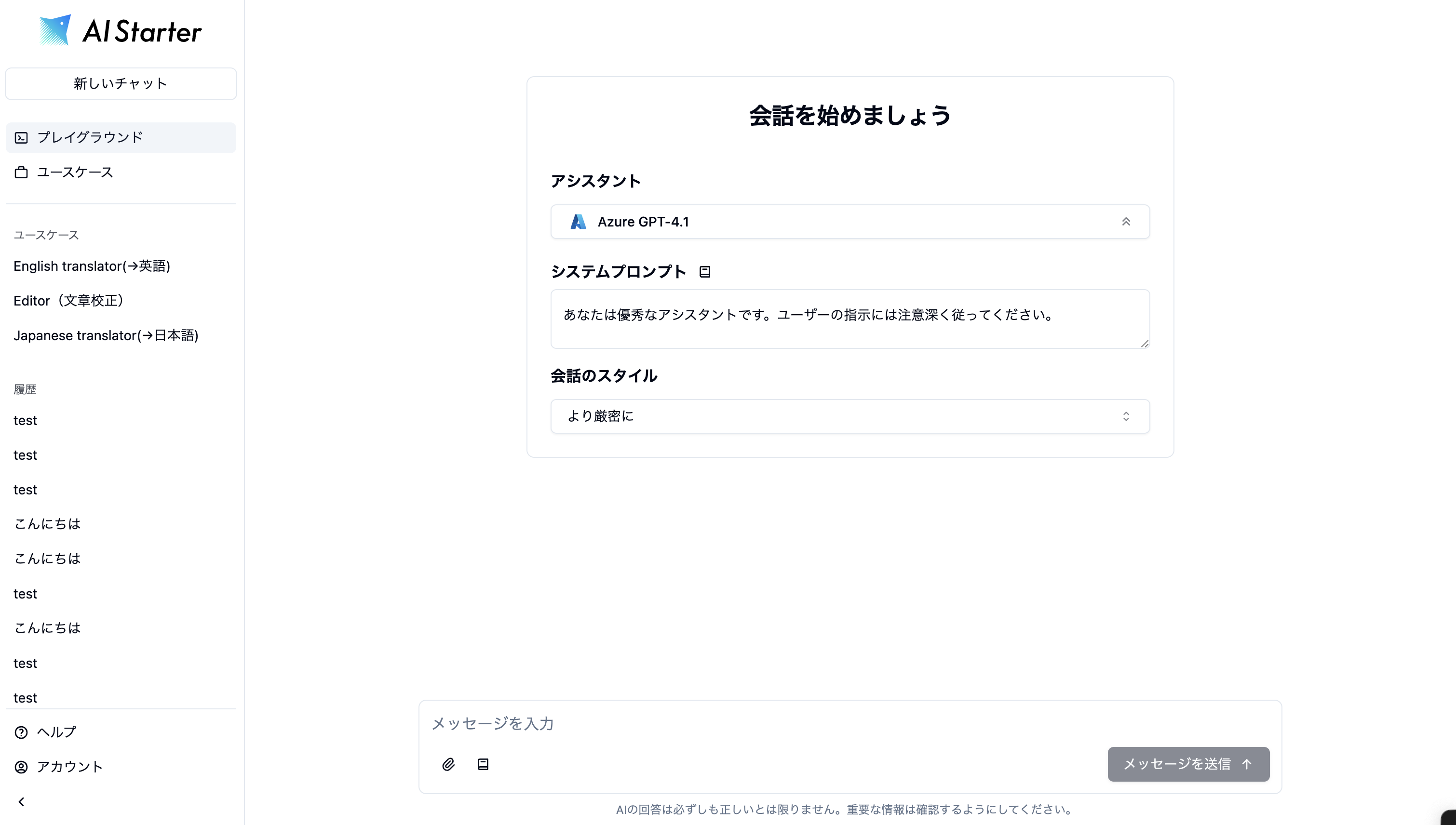
AI-Starter 2.4.15 の新機能予告でお知らせした通り、UI/UXの改善を行いました。 サイドバーの構成を見直し、より直感的な操作が可能な設計に刷新しました。 新しい構造は、将来的な機能追加や拡張に柔軟に対応できるよう考慮されています。 また、サイドバーの開閉機能を新たに追加し、ユーザーの利用シーンや好みに合わせてUIを調整できるようになりました。 さらに、プロンプトテンプレートのアイコン変更など、細かなUI改善も行いました。
4. 機能追加と改善
- Bedrockのプロンプトキャッシュ機能のサポート
- BedrockKnowledgeBasesRetrievalオプションの追加
- GoogleDriveFilesオプション(β版)の追加
- OpenAIResponsesAPIオプションの追加
Bedrockのプロンプトキャッシュ機能をサポートしました。 当該機能によって、Bedrockの一部のモデルで応答時間の短縮やコストの削減が実現されます。 AI-Starter内で自動適用されるため、管理者は設定を変更する必要はございません。
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/prompt-caching.html
BedrockKnowledgeBasesRetrievalオプションを追加しました。 これにより、BedrockのKnowledge Basesの検索を行いつつ、任意のモデルでRAGを実現できます。 RAGの精度や柔軟性を高めるために、Rerankingやフィルタリングなどの機能もサポート済みです。
Google Drive Retrievalオプション(β版)を追加しました。 これにより、指定したGoogle Driveのファイルの内容を会話に組み込むことができます。 現在、取り込むことが可能なファイルは、以下の通りです。
- Googleドキュメント
- Googleスプレッドシートの1シート目
OpenAIResponsesAPIオプションを追加しました。 Responses APIは、OpenAIの組み込みツールを活用してエージェントを構築するための新しいAPIです。 現在、Web検索とファイル検索の2つのツールをサポートしています。 今後、コードインタープリターやMCPなどのツールも提供される予定です。 手軽にエージェントを構築したい場合にご利用ください。
https://openai.com/index/new-tools-for-building-agents/
5. その他の細かなバグ修正・機能改善
その他の細かなバグ修正や機能改善を行いました。 一方で、サポート外となったモデルやオプションもあります。
以下はサポート外になったモデルです。 当該モデルを利用したアシスタントは引き続きご利用いただけますが、今後のアップデートに伴い不具合が生じる可能性があります。 性能やコスト面で優れた新しいモデルへの移行をお勧めいたします。
- Azure
- o1-mini(上位互換のo4-miniに置き換え)
- o3-mini(上位互換のo4-miniに置き換え)
- GPT-4.5 Preview(モデル廃止予定のため。GPT-4.1に置き換え)
- Google
- Gemini 2.0 Flash-Lite Preview(GA版のGemini 2.0 Flash-Liteに置き換え)
- Gemini 2.0 Pro Experimental(廃止のため)
- Gemini 1.5 Pro(上位互換のGemini 2.0シリーズに置き換え)
- OpenAI
- GPT-4.5 Preview(モデル廃止予定のため。GPT-4.1に置き換え)
- o1-mini(上位互換のo4-miniに置き換え)
- o3-mini(上位互換のo4-miniに置き換え)
- o1(上位互換のo3に置き換え)
以下はサポート外になったオプションです。
- BingSearchRetrieval(OpenAIのWeb検索機能付きモデルに置き換え)
おわりに
最後までお読みいただき、ありがとうございます。 AI-Starterは、ユーザーの皆様からのフィードバックを原動力に、継続的な改善に取り組んでいます。 今回のアップデート内容をご確認いただき、ご意見やご要望がございましたら、ぜひお寄せください。 皆様のご意見が、AI-Starterのさらなる進化につながります。 今後のアップデートにもご期待ください。